
Talk
Injecting Compliance into Code: Automating Compliance with AI in the MedTech SDLC


Randy Horton:
Next, we’re going to introduce Larkin Lowrey from Tandem Diabetes Care, who’s going to talk about a case study on automating for continuous delivery. I have to say, having seen these slides before, this is the best illustration I’ve come across to date of the impact of applying modern software engineering methods to our sector. I believe these methods and tools will not only accelerate software development but also raise the bar on how we think about quality. So with that, Larkin, I’ll turn it over to you.

Larkin Lowrey:
I’m Larkin Lowrey, Senior Director of Software Engineering for Digital Health at Tandem Diabetes. I started my career right at the very beginning of the Dot-com Era, and it was anarchy and bedlam. I spent a lot of my formative years in total chaos. For the last 20 years or so I’ve been in IoT.
I started out at a telematics company doing vehicle tracking and fleet management. We were a startup operating literally out of our garages. We didn’t have an actual office space for several months after we started. Despite that, we grew the company from a hardware company selling tracking devices, to a company that delivered data, reports and analytics to customers, to then delivering answers and solutions. As we grew from being a startup into a mature company, we had to learn how to produce quality. Quality was essential for building a successful company that could survive the startup birthing phase. We were eventually purchased by Verizon and became Verizon Telematics.
When I joined Tandem, which was about two years ago, it was a natural fit for me. Tandem produces an insulin pump. These pumps are just like the IoT devices you find running around the world. Our patients are using our mobile app to upload the data to us. We’re constantly collecting a stream of data into our system, and using that data to provide more intelligence back to the patient to help them manage their care. It’s in the name of our company: Tandem Diabetes Care. We’re not an insulin pump company, we’re a diabetes care company, and we deliver that care through intelligence.
What I want to talk about today is how we automate our processes that allow for continuous delivery. I’ll get into more details of what that means soon. But know that it’s really important for our business to have tight iteration cycles, so that we can continue to evolving connected medical device products and grow our technology and our understanding of the data.

What is continuous delivery? It’s a software engineering approach that has as its objective maintaining your code base in a production-ready state at all times. You don’t have a bunch of half-completed work sitting out there, festering, developing bugs, et cetera, that you then have to figure out how to merge together somewhere down the road. With continuous delivery, you are maintaining that code base in a clean and production-ready state every step of the way.
Why do we do that? We have short iteration cycles, which we do to reduce risk, and by reducing risk we also reduce cost and give ourselves a better time to market. We do it by employing the Agile methodology and by automating the heck out of everything. We can’t be fast, we can’t be thorough, we can’t verify that we’re production ready without the automation to confirm.

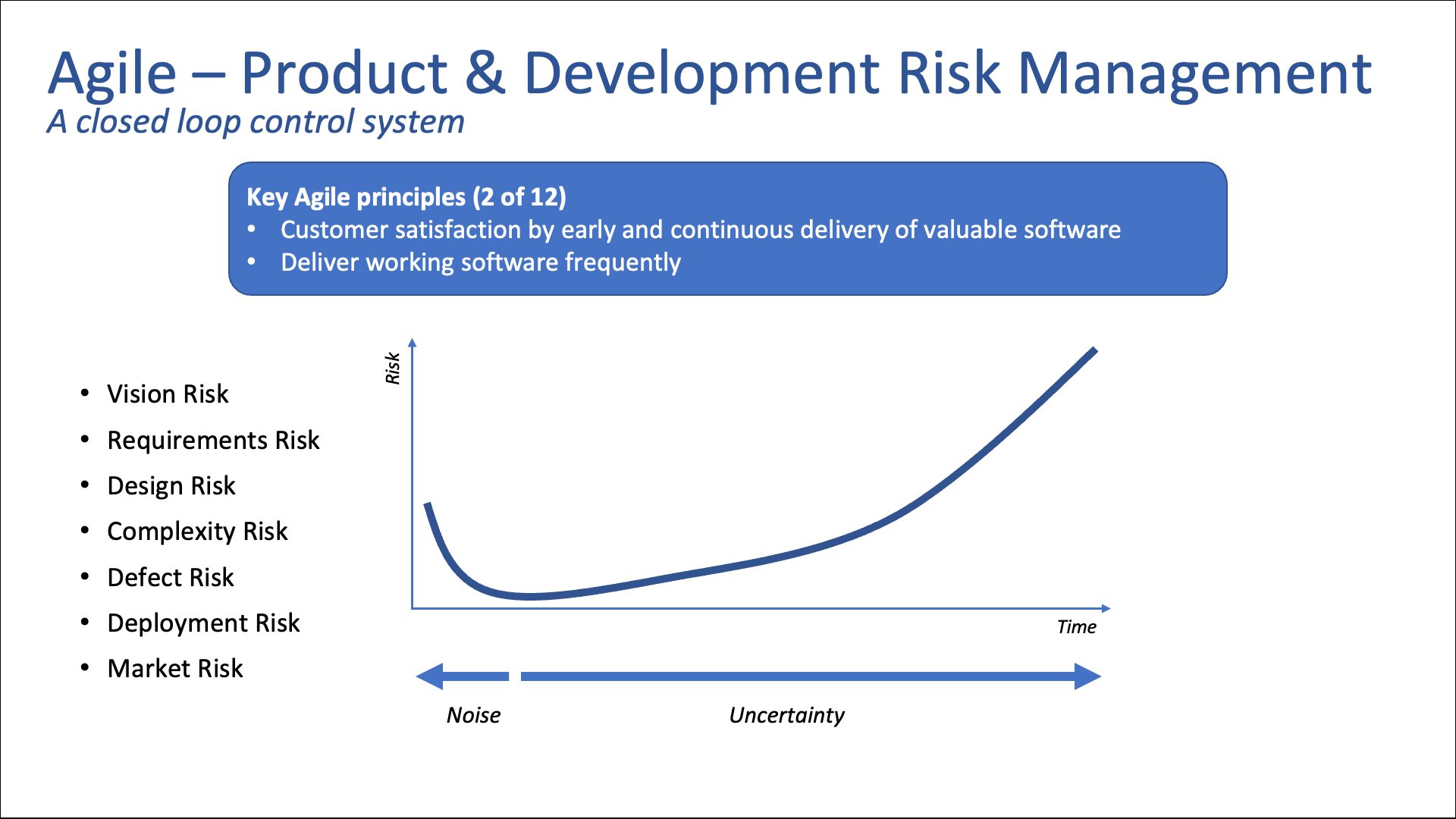
Let me talk about Agile for a bit. Agile means different things to different people. For me, Agile is a product development process, not a software engineering development process. It’s taking your cocktail napkin with a crazy idea through your development and testing validation process, all the way to delivery and to your customer.
I think of it as a closed loop control system, where you are sampling the environment, making decisions based upon that environment and iterating via development. Then, once you deliver that work product, you’re going to resample the environment and make decisions on how you go forward from there.
If we look at two of the 12 Key Principles of Agile,[1] we want to be delivering customer satisfaction very early and regularly by continuously releasing valuable software. And in this process, we want to be continuously delivering working software. Developers producing half-completed work doesn’t do anybody any good.
Back to the idea of Agile being a closed loop system. Every closed loop system operates in an open loop in between sampling intervals. The principle here is that as we are operating in an open loop, we are accumulating risk due to uncertainty. We can’t predict what is going to happen in the world two years from now, five years from now, 10 years from now.
Everybody likes to think they have a crystal ball and can predict what the world is going to be like a year from now. But the reality is that the further out we go, the more uncertain the world becomes, and the more risk we accumulate by running in this open loop mode for that duration.
This chart is trying to illustrate that we accumulate risk as we go forward in time, so we’re motivated to bring our timelines down in order to reduce that uncertainty. You do get to a point where if we get too short, we can’t optimize all the way back to zero because our inputs become very noisy. Our data becomes not statistically significant and we can’t depend on it.
We have to find that sweet spot. I would suggest that you consider the sweet spot to be on the order of weeks and not months, but every industry, every product, is going to be a little bit different on that front. Basically, we’re trying to reduce risk by iterating quickly, and believe it or not, this is a case where going faster is safer.

I always love to bring out the Royal Society’s motto. For 400 years, it’s been Nullius in verba: “Take nobody’s word for it.”[2] It’s probably one of the most important concepts ever developed by our squishy monkey brains. Basically, it means a claim has no utility unless it can be independently validated or verified or confirmed. I can claim that I’ve just spotted Bigfoot, for example. I could be the most successful and reliable monster detector of all time. All of my previous claims could have been rock-solid. But if you can’t independently verify my claim that I just saw Bigfoot, that information is meaningless.
You can’t build new knowledge based upon meaningless information. You always have to verify. We take this philosophy and we apply it to software engineering. We believe that if a developer delivers code to us, they’re making a claim that what they’ve delivered works. If we don’t have an ability to independently verify that the code actually does what it’s supposed to do, that it meets the requirements, satisfies all the acceptance criteria, et cetera, then that code doesn’t exist.
We ask our software engineers to deliver the code and the test that proves that it works or that it exists at the same time. If they can’t produce that proof, that code doesn’t exist and we don’t accept it. In our industry, we like to say: If it’s not documented, it didn’t happen. How do we not only prove to ourselves that we’re producing quality, but how do we prove to others that we’re producing quality? In the outside world, we can get to continuous delivery just through our software test automation, but we have to do more. We have to actually produce our documentation.

Let me create a bit of a glossary here so that we’re talking about the same thing. CI/CD pipelines are central to what we’re going to talk about. You all have them. The CI stands for continuous integration. This is the system that is going to build your software and run your unit and integration tests. It’s going to prove that the code the developers are producing works, and that it will integrate with the rest of the system.
CD can mean two different things. In this context, we’re talking about continuous delivery, making sure that the code is always production-ready. In the outside world, CD can also mean continuous deployment, where the decision to deploy is actually automated. If the code passes all of the tests, then the system will automatically push that code out to production. We can’t do that – we have to have human review. So we’re going to be focusing on continuous delivery.

This slide here is supposed to look like requirements. (My requirements writing permit was taken away a long time ago, so cut me a little slack here.) I’m trying to illustrate a simple requirement that you might have for a web application. Imagine a user is going to log into your web app. Depending on the role of that user, they’re going to end up on a different landing page. The system has to know what role you are, and then make sure that you end up on the right page.
Here we have two different scenarios for our acceptance criteria. In the first scenario, we’ve defined that if the user puts in credentials for a regular user, then they’re going to get the regular user dashboard view. The second scenario is if you’re going to put in your admin user’s credentials, we want to make sure that you end up on the admin view.
This language should look very familiar to your product owners. It should look very familiar to everybody working with requirements. We’ll talk more about what this file actually is, and how it fits into the overall pipeline, but I just want to illustrate that we’re treating requirements as code, we’re including it as part of our source code, and we’re using it to enable our test automation. Each of these scenarios can be plugged directly into our test automation code and executed directly as our test automation.
This method is not just useful for encoding our requirements and as an input to our test automation. We can do other cool things with it.

This file format allows for annotations, which are these at sign prefixed tags here. We can add tags that allow us to do some pretty interesting things.

We can grab the ID tag from the feature line and descriptive text for the feature, then use that to generate our product requirements document. Our source of truth for our product requirements is now this Gherkin file, which is included with our source code. We can use this file to generate our product requirements specification (PRS). [3]

We then grab some additional content here that we are using for each scenario. Now we’re generating our software requirements document (SRS)[4] as an artifact that is generated from our software build process. Again, this becomes a source of truth for our software requirements.

We’re then able to take this content indicated in yellow to create our software validation protocols (SVAPs).[5] Just like the code above, this is our source of truth, and we’re automatically generating these documents that we need to maintain.

There’s a little bit of a twist here. See how the red arrow in the lower left is pointing to this manual tag? Not every test that we’re going to have is going to be automatable. Maybe it’s not practical to automate it. Maybe we don’t have the time. Whatever it is, there are going to be certain tests that are manual. But now that we know which tests are automated and which tests are manual, we can then use this file to run all of our automated tests.
We’re now able to generate two SVAPs – one for all of our automated tests and one for all of the tests we indicated are manual. Then we can give that manual SVAP document to our test engineers and say, go run these tests, and only these tests. That’s great.
Another thing that we get out of this is that we can build and generate our requirements traceability matrix (RTM).[6] We know what our requirements are, we know what tests we’re going to run, and for the automated test we know that they were run and whether they passed or failed.
For our automated test, we can generate a complete RTM. For the manual tests, we have a second RTM that covers just the manual tests. We hand that document along with the manual SVAP over to our test engineers, and they complete that process manually.
The other really cool part is that as the software developers start to add more and more automation, they’re able to convert a manual test to an automated test and remove the manual tag. Every test where they remove the manual tag corresponds to that tag automatically being removed from the manual SVAP and the manual RTM.
It shrinks the workload of the test engineering team in a way where they don’t have to figure out which tests are automated and which ones aren’t. They know exactly what they have to do because we’re delivering them their SVAP and their RTM that are specifically tuned for exactly the testing that they need to do. This is extremely powerful and really enables a tremendous amount of automation for us.
Gherkin to the Rescue
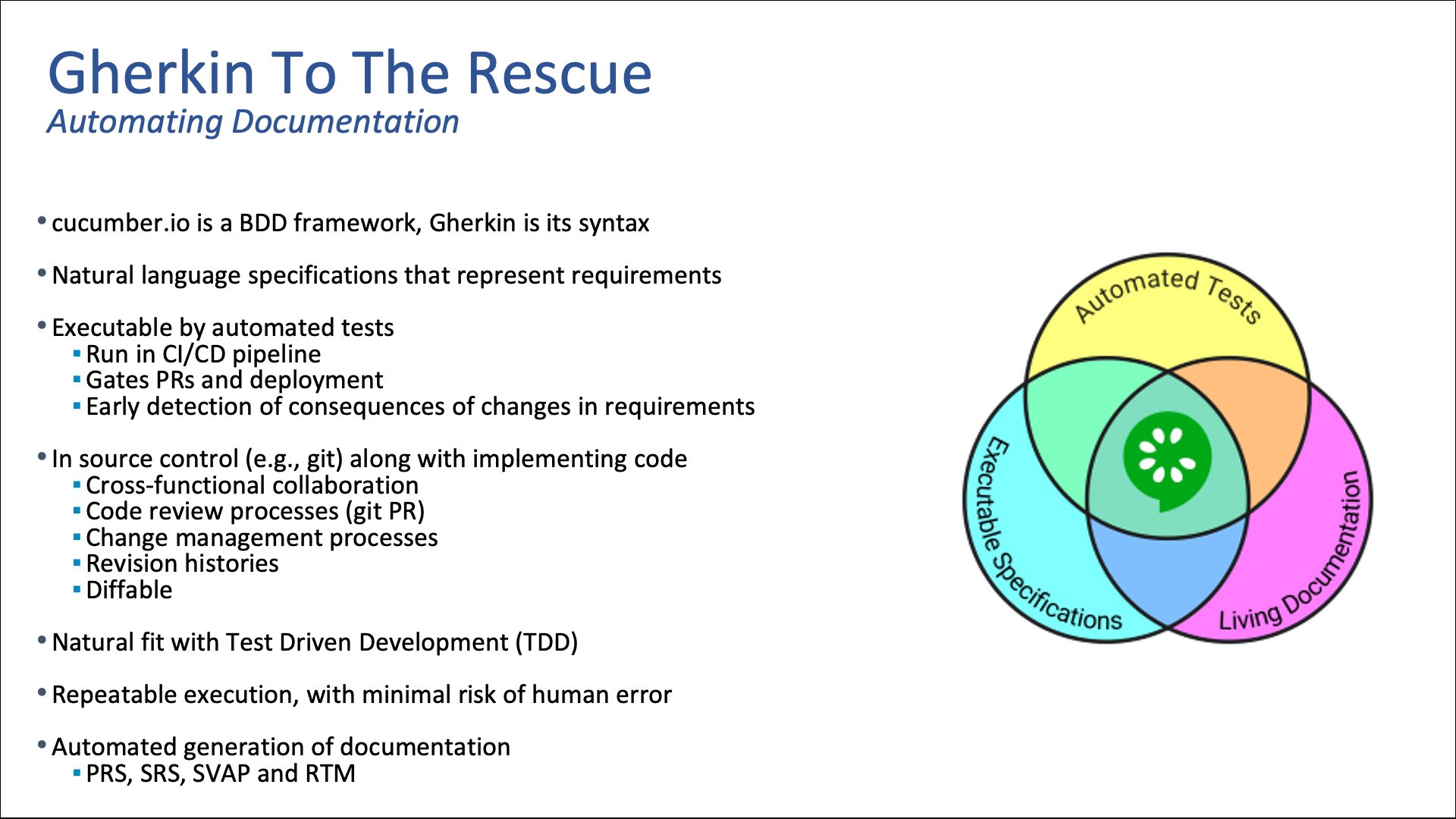
The file format syntax I just showed you is called Gherkin. It’s part of a behavior driven design framework called Cucumber, which uses natural language specifications that represent requirements and acceptance criteria. We plug Gherkin files directly into our automated testing framework. It runs as part of our CI/CD pipelines, and because of that, we can use it to gate our pull requests.
When our developers submit their code, if their code doesn’t pass all of the tests as specified in the Gherkin spec, we reject that pull request. When peer reviews and quality assurance reviews can assert that yes, all the requirements are being met and satisfied by the tests, that pull request gets approved. We’re also gating deployment, so we’re not going to push anything that doesn’t pass all of those tests as specified by the Gherkin spec.
Another really handy aspect of this is that requirements do change from time to time. When a change to requirements is made, it’s made to the Gherkin file, which is co-located with the source code. That change immediately triggers a new CI/CD build, which will then test everything again. If that change to requirements produces any failures or has any kind of downstream consequences, we can detect it immediately. That’s an extremely powerful function.
As I mentioned, we store the Gherkin files along with our source code in our source code repository. (Hopefully you’re using Git.) This enables cross-functional collaboration. Your product owner is cooperating with the developers, test engineers, business analysts and whoever else you have working on your requirements. They’re all working together in the same Git repo. All of your change management processes that you have for your source code applies to these Gherkin files as well, which means that any new requirements, changes to requirements or acceptance criteria have to be peer reviewed.
You can set, through your change management process whatever approvals are necessary to get these changes into the system. In Git, all of the change history and the source code you’re managing through that repository is right there. And because it’s in that same source control repository, you have the ability to compare requirements over time. The system will tell you exactly what changed within the requirements or the acceptance criteria between time A and time B.
This is all a natural fit with test-driven development. Because you are handing the developer the Gherkin script first, the first thing they’re going to do is write the test automation to test the requirements. And because it’s all automated, you have repeatable execution: You can run the same tests a million times without the human error associated with running manual tests. And as I mentioned, we’re generating a good bit of our documentation through this process, such as PRS, SRS, SVAP and RTM.

I wanted to illustrate two projects of ours here for you. Project One is a big project. So far, we only have about 65% of our requirements automated. It takes us four weeks to get through verification and validation (V&V), which is unpleasant and painful.
Project Two, to be fair, is smaller than Project One – it’s about half the size. But we’re almost finished automating the requirements. If you had to guess, what’s our time to release for Project Two? Maybe a week, maybe two weeks?

The answer: It takes us two hours to completely validate Project Two’s software. It’ll take a bit longer to get all of the e-signatures, have our ceremonial meetings and gather other various approvals. But this means that multiple times a day, we can validate that our code is production ready. We know if we’re meeting our requirements and if we’re not. It’s incredibly liberating for our teams. It enables a tremendous amount of productivity. I can’t undersell the value of having the ability to rerun V&V multiple times a day with very little effort.
It’s Faster – So What?

You might think, “It’s faster. Big deal. What does that really give you?” What it gives you is the ability to release more quickly to your customers with greater confidence, so customers are happier that they’re getting more value faster. It gives us earlier feedback from the market. It allows us to iterate more quickly. We’re able to use those inputs from releasing more quickly to inform our future designs and our future iterations.
We’re actually producing higher quality products because we’re reducing the risk of human error and we’re producing much more comprehensive testing. Not to mention that we’re doing it at a lower cost – machines are a lot cheaper than people.
Because of this tool, we have less reliance on variable human resources. I’m sure all of you guys have what I call “QA nomads” that roam from project to project, depending on who needs to be doing V&V at any given time. Obviously, handcrafting an RTM is fraught with error. When executing your SVAPs manually and keeping track by hand, there’s a higher risk of typos or manual error during the execution of the tests.
With our method, we can cut out a lot of risk. We can reduce the number of small numerical errors in acceptance criteria, and we’ve limited the number of manual tests and the workflow that you have to do to record all of these manual tests into that RTM. Plus, it allows for greater collaboration between all of the different stakeholders involved in this process.
Overall, it’s been an extremely powerful tool for us. It’s literally taking over our world. I highly recommend it. Thank you.
Randy Horton:
Thank you, Larkin. That was a lot of great content. We’ve received a bunch of detailed questions from this for our Q&A later, so we really appreciate it.
Below is a list of the other sections of our Move Faster & Break Nothing Webinar:
References 1. 12 Principles Behind the Agile Manifesto | Agile Alliance https://www.agilealliance.org/agile101/12-principles-behind-the-agile-manifesto/. Published 2021. Accessed January 3, 2022. 2. History of the Royal Society |Royalsociety.org. https://royalsociety.org/about-us/history/. Published 2020. Accessed January 3, 2022. 3. Product Requirements Specification [DesignWIKI]. Deseng.ryerson.ca. https://deseng.ryerson.ca/dokuwiki/design:product_requirements_specification. Published 2021. Accessed January 6, 2022. 4. Content of Premarket Submissions for Device Software Functions. Fda.gov. https://www.fda.gov/media/153781/download. Published 2021. Accessed January 3, 2022. 5. Software Verification and Validation (V&V) Overview and must-have Documents. Complianceonline.com. https://www.complianceonline.com/resources/software-verification-and-validation-overview-and-must-have-documents.html. Published 2021. Accessed January 3, 2022. 6. Traceability matrix - Wikipedia. En.wikipedia.org. https://en.wikipedia.org/wiki/Traceability_matrix. Published 2021. Accessed January 3, 2022.
Related Posts
Talk
Injecting Compliance into Code: Automating Compliance with AI in the MedTech SDLC

Talk
Beyond the Device: Where Digital Ecosystems Are Creating Real Value in MedTech

Talk
Cloud-Native Architecture (What You Should Learn from Amazon, Google and Microsoft for MedTech)

Talk
How to Create an Agile Organizational Structure
